Architecture¶
Versioning¶
This document describes Zenko CloudServer’s support for the AWS S3 Bucket Versioning feature.
AWS S3 Bucket Versioning¶
See AWS documentation for a description of the Bucket Versioning feature:
This document assumes familiarity with the details of Bucket Versioning, including null versions and delete markers, described in the above links.
Implementation of Bucket Versioning in Zenko CloudServer¶
Overview of Metadata and API Component Roles¶
Each version of an object is stored as a separate key in metadata. The S3 API interacts with the metadata backend to store, retrieve, and delete version metadata.
The implementation of versioning within the metadata backend is naive. The metadata backend does not evaluate any information about bucket or version state (whether versioning is enabled or suspended, and whether a version is a null version or delete marker). The S3 front-end API manages the logic regarding versioning information, and sends instructions to metadata to handle the basic CRUD operations for version metadata.
The role of the S3 API can be broken down into the following:
- put and delete version data
- store extra information about a version, such as whether it is a delete marker or null version, in the object’s metadata
- send instructions to metadata backend to store, retrieve, update and delete version metadata based on bucket versioning state and version metadata
- encode version ID information to return in responses to requests, and decode version IDs sent in requests
The implementation of Bucket Versioning in S3 is described in this document in two main parts. The first section, “Implementation of Bucket Versioning in Metadata”, describes the way versions are stored in metadata, and the metadata options for manipulating version metadata.
The second section, “Implementation of Bucket Versioning in API”, describes the way the metadata options are used in the API within S3 actions to create new versions, update their metadata, and delete them. The management of null versions and creation of delete markers is also described in this section.
Implementation of Bucket Versioning in Metadata¶
As mentioned above, each version of an object is stored as a separate key in metadata. We use version identifiers as the suffix for the keys of the object versions, and a special version (the “Master Version”) to represent the latest version.
An example of what the metadata keys might look like for an object
foo/bar with three versions (with . representing a null character):
| key |
|---|
| foo/bar |
| foo/bar.098506163554375999999PARIS 0.a430a1f85c6ec |
| foo/bar.098506163554373999999PARIS 0.41b510cd0fdf8 |
| foo/bar.098506163554373999998PARIS 0.f9b82c166f695 |
The most recent version created is represented above in the key
foo/bar and is the master version. This special version is described
further in the section “Master Version”.
Version ID and Metadata Key Format¶
The version ID is generated by the metadata backend, and encoded in a hexadecimal string format by S3 before sending a response to a request. S3 also decodes the hexadecimal string received from a request before sending to metadata to retrieve a particular version.
The format of a version_id is: ts rep_group_id seq_id
where:
ts: is the combination of epoch and an increasing numberrep_group_id: is the name of deployment(s) considered one unit used for replicationseq_id: is a unique value based on metadata information.
The format of a key in metadata for a version is:
object_name separator version_id where:
object_name: is the key of the object in metadataseparator: we use thenullcharacter (0x00or\0) as the separator between theobject_nameand theversion_idof a keyversion_id: is the version identifier; this encodes the ordering information in the format described above as metadata orders keys alphabetically
An example of a key in metadata:
foo\01234567890000777PARIS 1234.123456 indicating that this specific
version of foo was the 000777th entry created during the epoch
1234567890 in the replication group PARIS with 1234.123456
as seq_id.
Master Version¶
We store a copy of the latest version of an object’s metadata using
object_name as the key; this version is called the master version.
The master version of each object facilitates the standard GET
operation, which would otherwise need to scan among the list of versions
of an object for its latest version.
The following table shows the layout of all versions of foo in the
first example stored in the metadata (with dot . representing the
null separator):
| key | value |
|---|---|
| foo | B |
| foo.v2 | B |
| foo.v1 | A |
Metadata Versioning Options¶
Zenko CloudServer sends instructions to the metadata engine about whether to create a new version or overwrite, retrieve, or delete a specific version by sending values for special options in PUT, GET, or DELETE calls to metadata. The metadata engine can also list versions in the database, which is used by Zenko CloudServer to list object versions.
These only describe the basic CRUD operations that the metadata engine can handle. How these options are used by the S3 API to generate and update versions is described more comprehensively in “Implementation of Bucket Versioning in API”.
Note: all operations (PUT and DELETE) that generate a new version of an
object will return the version_id of the new version to the API.
PUT¶
- no options: original PUT operation, will update the master version
versioning: truecreate a new version of the object, then update the master version with this version.versionId: <versionId>create or update a specific version (for updating version’s ACL or tags, or remote updates in geo-replication)- if the version identified by
versionIdhappens to be the latest version, the master version will be updated as well - if the master version is not as recent as the version identified by
versionId, as may happen with cross-region replication, the master will be updated as well - note that with
versionIdset to an empty string'', it will overwrite the master version only (same as no options, but the master version will have aversionIdproperty set in its metadata like any other version). TheversionIdwill never be exposed to an external user, but setting this internal-onlyversionIDenables Zenko CloudServer to find this version later if it is no longer the master. This option ofversionIdset to''is used for creating null versions once versioning has been suspended, which is discussed in “Null Version Management”.
- if the version identified by
In general, only one option is used at a time. When versionId and
versioning are both set, only the versionId option will have an effect.
DELETE¶
- no options: original DELETE operation, will delete the master version
versionId: <versionId>delete a specific version
A deletion targeting the latest version of an object has to:
delete the specified version identified by
versionIdreplace the master version with a version that is a placeholder for deletion
- this version contains a special keyword, ‘isPHD’, to indicate the
- master version was deleted and needs to be updated
initiate a repair operation to update the value of the master version:
- involves listing the versions of the object and get the latest version to replace the placeholder delete version
- if no more versions exist, metadata deletes the master version, removing the key from metadata
Note: all of this happens in metadata before responding to the front-end api, and only when the metadata engine is instructed by Zenko CloudServer to delete a specific version or the master version. See section “Delete Markers” for a description of what happens when a Delete Object request is sent to the S3 API.
GET¶
- no options: original GET operation, will get the master version
versionId: <versionId>retrieve a specific version
The implementation of a GET operation does not change compared to the standard version. A standard GET without versioning information would get the master version of a key. A version-specific GET would retrieve the specific version identified by the key for that version.
LIST¶
For a standard LIST on a bucket, metadata iterates through the keys by
using the separator (\0, represented by . in examples) as an
extra delimiter. For a listing of all versions of a bucket, there is no
change compared to the original listing function. Instead, the API
component returns all the keys in a List Objects call and filters for
just the keys of the master versions in a List Object Versions call.
For example, a standard LIST operation against the keys in a table below
would return from metadata the list of
[ foo/bar, bar, qux/quz, quz ].
| key |
|---|
| foo/bar |
| foo/bar.v2 |
| foo/bar.v1 |
| bar |
| qux/quz |
| qux/quz.v2 |
| qux/quz.v1 |
| quz |
| quz.v2 |
| quz.v1 |
Implementation of Bucket Versioning in API¶
Object Metadata Versioning Attributes¶
To access all the information needed to properly handle all cases that may exist in versioned operations, the API stores certain versioning-related information in the metadata attributes of each version’s object metadata.
These are the versioning-related metadata properties:
isNull: whether the version being stored is a null version.nullVersionId: the unencoded version ID of the latest null version that existed before storing a non-null version.isDeleteMarker: whether the version being stored is a delete marker.
The metadata engine also sets one additional metadata property when creating the version.
versionId: the unencoded version ID of the version being stored.
Null versions and delete markers are described in further detail in their own subsections.
Creation of New Versions¶
When versioning is enabled in a bucket, APIs which normally result in the creation of objects, such as Put Object, Complete Multipart Upload and Copy Object, will generate new versions of objects.
Zenko CloudServer creates a new version and updates the master version using the
versioning: true option in PUT calls to the metadata engine. As an
example, when two consecutive Put Object requests are sent to the Zenko
CloudServer for a versioning-enabled bucket with the same key names, there
are two corresponding metadata PUT calls with the versioning option
set to true.
The PUT calls to metadata and resulting keys are shown below:
- PUT foo (first put), versioning:
true
| key | value |
|---|---|
| foo | A |
| foo.v1 | A |
- PUT foo (second put), versioning:
true
| key | value |
|---|---|
| foo | B |
| foo.v2 | B |
| foo.v1 | A |
Null Version Management¶
In a bucket without versioning, or when versioning is suspended, putting an object with the same name twice should result in the previous object being overwritten. This is managed with null versions.
Only one null version should exist at any given time, and it is identified in Zenko CloudServer requests and responses with the version id “null”.
Case 1: Putting Null Versions¶
With respect to metadata, since the null version is overwritten by
subsequent null versions, the null version is initially stored in the
master key alone, as opposed to being stored in the master key and a new
version. Zenko CloudServer checks if versioning is suspended or has never been
configured, and sets the versionId option to '' in PUT calls to
the metadata engine when creating a new null version.
If the master version is a null version, Zenko CloudServer also sends a DELETE call to metadata prior to the PUT, in order to clean up any pre-existing null versions which may, in certain edge cases, have been stored as a separate version. [1]
The tables below summarize the calls to metadata and the resulting keys if we put an object ‘foo’ twice, when versioning has not been enabled or is suspended.
- PUT foo (first put), versionId:
''
| key | value |
|---|---|
| foo (null) | A |
(2A) DELETE foo (clean-up delete before second put),
versionId: <version id of master version>
| key | value |
|---|---|
(2B) PUT foo (second put), versionId: ''
| key | value |
|---|---|
| foo (null) | B |
The S3 API also sets the isNull attribute to true in the version
metadata before storing the metadata for these null versions.
| [1] | (1, 2) Some examples of these cases are: (1) when there is a null version that is the second-to-latest version, and the latest version has been deleted, causing metadata to repair the master value with the value of the null version and (2) when putting object tag or ACL on a null version that is the master version, as explained in “Behavior of Object-Targeting APIs”. |
Case 2: Preserving Existing Null Versions in Versioning-Enabled Bucket¶
Null versions are preserved when new non-null versions are created after versioning has been enabled or re-enabled.
If the master version is the null version, the S3 API preserves the
current null version by storing it as a new key (3A) in a separate
PUT call to metadata, prior to overwriting the master version (3B).
This implies the null version may not necessarily be the latest or
master version.
To determine whether the master version is a null version, the S3 API
checks if the master version’s isNull property is set to true,
or if the versionId attribute of the master version is undefined
(indicating it is a null version that was put before bucket versioning
was configured).
Continuing the example from Case 1, if we enabled versioning and put another object, the calls to metadata and resulting keys would resemble the following:
(3A) PUT foo, versionId: <versionId of master version> if defined or
<non-versioned object id>
| key | value |
|---|---|
| foo | B |
| foo.v1 (null) | B |
(3B) PUT foo, versioning: true
| key | value |
|---|---|
| foo | C |
| foo.v2 | C |
| foo.v1 (null) | B |
To prevent issues with concurrent requests, Zenko CloudServer ensures the null
version is stored with the same version ID by using versionId option.
Zenko CloudServer sets the versionId option to the master version’s
versionId metadata attribute value during the PUT. This creates a new
version with the same version ID of the existing null master version.
The null version’s versionId attribute may be undefined because it
was generated before the bucket versioning was configured. In that case,
a version ID is generated using the max epoch and sequence values
possible so that the null version will be properly ordered as the last
entry in a metadata listing. This value (“non-versioned object id”) is
used in the PUT call with the versionId option.
Case 3: Overwriting a Null Version That is Not Latest Version¶
Normally when versioning is suspended, Zenko CloudServer uses the
versionId: '' option in a PUT to metadata to create a null version.
This also overwrites an existing null version if it is the master version.
However, if there is a null version that is not the latest version,
Zenko CloudServer cannot rely on the versionId: '' option will not
overwrite the existing null version. Instead, before creating a new null
version, the Zenko CloudServer API must send a separate DELETE call to metadata
specifying the version id of the current null version for delete.
To do this, when storing a null version (3A above) before storing a new
non-null version, Zenko CloudServer records the version’s ID in the
nullVersionId attribute of the non-null version. For steps 3A and 3B above,
these are the values stored in the nullVersionId of each version’s metadata:
(3A) PUT foo, versioning: true
| key | value | value.nullVersionId |
|---|---|---|
| foo | B | undefined |
| foo.v1 (null) | B | undefined |
(3B) PUT foo, versioning: true
| key | value | value.nullVersionId |
|---|---|---|
| foo | C | v1 |
| foo.v2 | C | v1 |
| foo.v1 (null) | B | undefined |
If defined, the nullVersionId of the master version is used with the
versionId option in a DELETE call to metadata if a Put Object
request is received when versioning is suspended in a bucket.
(4A) DELETE foo, versionId: <nullVersionId of master version> (v1)
| key | value |
|---|---|
| foo | C |
| foo.v2 | C |
Then the master version is overwritten with the new null version:
(4B) PUT foo, versionId: ''
| key | value |
|---|---|
| foo (null) | D |
| foo.v2 | C |
The nullVersionId attribute is also used to retrieve the correct
version when the version ID “null” is specified in certain object-level
APIs, described further in the section “Null Version
Mapping”.
Specifying Versions in APIs for Putting Versions¶
Since Zenko CloudServer does not allow an overwrite of existing version data,
Put Object, Complete Multipart Upload and Copy Object return
400 InvalidArgument if a specific version ID is specified in the
request query, e.g. for a PUT /foo?versionId=v1 request.
PUT Example¶
When Zenko CloudServer receives a request to PUT an object:
- It checks first if versioning has been configured
- If it has not been configured, Zenko CloudServer proceeds to puts the new data, puts the metadata by overwriting the master version, and proceeds to delete any pre-existing data
If versioning has been configured, Zenko CloudServer checks the following:
Versioning Enabled¶
If versioning is enabled and there is existing object metadata:
- If the master version is a null version (
isNull: true) or has no version ID (put before versioning was configured):- store the null version metadata as a new version
- create a new version and overwrite the master version
- set
nullVersionId: version ID of the null version that was stored
- set
If versioning is enabled and the master version is not null; or there is no existing object metadata:
- create a new version and store it, and overwrite the master version
Versioning Suspended¶
If versioning is suspended and there is existing object metadata:
If the master version has no version ID:
- overwrite the master version with the new metadata (PUT
versionId: '') - delete previous object data
- overwrite the master version with the new metadata (PUT
If the master version is a null version:
- delete the null version using the versionId metadata attribute of the
master version (PUT
versionId: <versionId of master object MD>) - put a new null version (PUT
versionId: '')
- delete the null version using the versionId metadata attribute of the
master version (PUT
If master is not a null version and
nullVersionIdis defined in the object’s metadata:- delete the current null version metadata and data
- overwrite the master version with the new metadata
If there is no existing object metadata, create the new null version as the master version.
In each of the above cases, set isNull metadata attribute to true
when creating the new null version.
Behavior of Object-Targeting APIs¶
API methods which can target existing objects or versions, such as Get
Object, Head Object, Get Object ACL, Put Object ACL, Copy Object and
Copy Part, will perform the action on the latest version of an object if
no version ID is specified in the request query or relevant request
header (x-amz-copy-source-version-id for Copy Object and Copy Part
APIs).
Two exceptions are the Delete Object and Multi-Object Delete APIs, which will instead attempt to create delete markers, described in the following section, if no version ID is specified.
No versioning options are necessary to retrieve the latest version from
metadata, since the master version is stored in a key with the name of
the object. However, when updating the latest version, such as with the
Put Object ACL API, Zenko CloudServer sets the versionId option in the
PUT call to metadata to the value stored in the object metadata’s versionId
attribute. This is done in order to update the metadata both in the
master version and the version itself, if it is not a null version. [2]
When a version id is specified in the request query for these APIs, e.g.
GET /foo?versionId=v1, Zenko CloudServer will attempt to decode the version
ID and perform the action on the appropriate version. To do so, the API sets
the value of the versionId option to the decoded version ID in the
metadata call.
Delete Markers¶
If versioning has not been configured for a bucket, the Delete Object and Multi-Object Delete APIs behave as their standard APIs.
If versioning has been configured, Zenko CloudServer deletes object or version
data only if a specific version ID is provided in the request query, e.g.
DELETE /foo?versionId=v1.
If no version ID is provided, S3 creates a delete marker by creating a
0-byte version with the metadata attribute isDeleteMarker: true. The
S3 API will return a 404 NoSuchKey error in response to requests
getting or heading an object whose latest version is a delete maker.
To restore a previous version as the latest version of an object, the delete marker must be deleted, by the same process as deleting any other version.
The response varies when targeting an object whose latest version is a delete marker for other object-level APIs that can target existing objects and versions, without specifying the version ID.
- Get Object, Head Object, Get Object ACL, Object Copy and Copy Part
return
404 NoSuchKey. - Put Object ACL and Put Object Tagging return
405 MethodNotAllowed.
These APIs respond to requests specifying the version ID of a delete
marker with the error 405 MethodNotAllowed, in general. Copy Part
and Copy Object respond with 400 Invalid Request.
See section “Delete Example” for a summary.
Null Version Mapping¶
When the null version is specified in a request with the version ID
“null”, the S3 API must use the nullVersionId stored in the latest
version to retrieve the current null version, if the null version is not
the latest version.
Thus, getting the null version is a two step process:
- Get the latest version of the object from metadata. If the latest
version’s
isNullproperty istrue, then use the latest version’s metadata. Otherwise, - Get the null version of the object from metadata, using the internal
version ID of the current null version stored in the latest version’s
nullVersionIdmetadata attribute.
DELETE Example¶
The following steps are used in the delete logic for delete marker creation:
- If versioning has not been configured: attempt to delete the object
- If request is version-specific delete request: attempt to delete the version
- otherwise, if not a version-specific delete request and versioning
has been configured:
- create a new 0-byte content-length version
- in version’s metadata, set a ‘isDeleteMarker’ property to true
- Return the version ID of any version deleted or any delete marker created
- Set response header
x-amz-delete-markerto true if a delete marker was deleted or created
The Multi-Object Delete API follows the same logic for each of the objects or versions listed in an xml request. Note that a delete request can result in the creation of a deletion marker even if the object requested to delete does not exist in the first place.
Object-level APIs which can target existing objects and versions perform the following checks regarding delete markers:
- If not a version-specific request and versioning has been configured, check the metadata of the latest version
- If the ‘isDeleteMarker’ property is set to true, return
404 NoSuchKeyor405 MethodNotAllowed - If it is a version-specific request, check the object metadata of the requested version
- If the
isDeleteMarkerproperty is set to true, return405 MethodNotAllowedor400 InvalidRequest
| [2] | If it is a null version, this call will overwrite the null version
if it is stored in its own key (foo\0<versionId>). If the null
version is stored only in the master version, this call will both
overwrite the master version and create a new key
(foo\0<versionId>), resulting in the edge case referred to by the
previous footnote [1]. |
Data-metadata daemon Architecture and Operational guide¶
This document presents the architecture of the data-metadata daemon (dmd) used for the community edition of Zenko CloudServer. It also provides a guide on how to operate it.
The dmd is responsible for storing and retrieving Zenko CloudServer data and metadata, and is accessed by Zenko CloudServer connectors through socket.io (metadata) and REST (data) APIs.
It has been designed such that more than one Zenko CloudServer connector can access the same buckets by communicating with the dmd. It also means that the dmd can be hosted on a separate container or machine.
Operation¶
Startup¶
The simplest deployment is still to launch with yarn start, this will start one instance of the Zenko CloudServer connector and will listen on the locally bound dmd ports 9990 and 9991 (by default, see below).
The dmd can be started independently from the Zenko CloudServer by running this command in the Zenko CloudServer directory:
yarn run start_dmd
This will open two ports:
- one is based on socket.io and is used for metadata transfers (9990 by default)
- the other is a REST interface used for data transfers (9991 by default)
Then, one or more instances of Zenko CloudServer without the dmd can be started elsewhere with:
yarn run start_s3server
Configuration¶
Most configuration happens in config.json for Zenko CloudServer, local
storage paths can be changed where the dmd is started using environment
variables, like before: S3DATAPATH and S3METADATAPATH.
In config.json, the following sections are used to configure access
to the dmd through separate configuration of the data and metadata
access:
"metadataClient": {
"host": "localhost",
"port": 9990
},
"dataClient": {
"host": "localhost",
"port": 9991
},
To run a remote dmd, you have to do the following:
- change both
"host"attributes to the IP or host name where the dmd is run. - Modify the
"bindAddress"attributes in"metadataDaemon"and"dataDaemon"sections where the dmd is run to accept remote connections (e.g."::")
Architecture¶
This section gives a bit more insight on how it works internally.
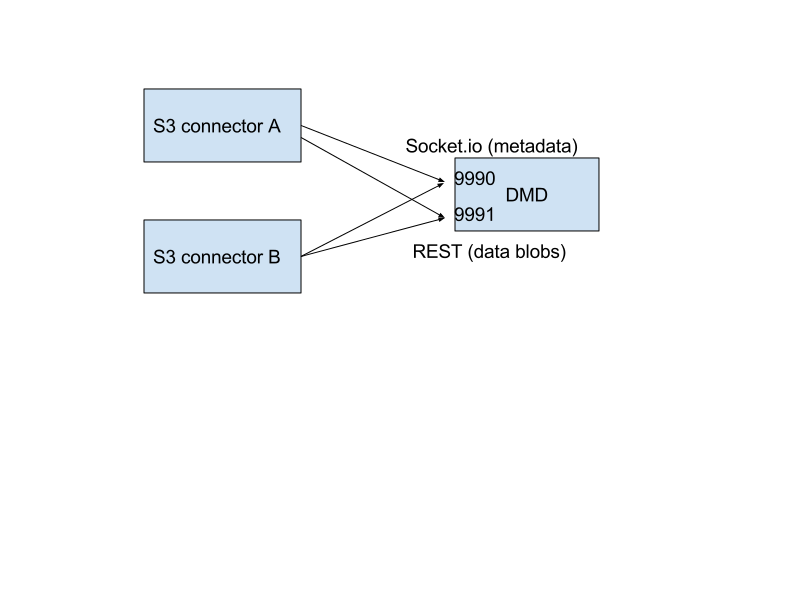
./images/data_metadata_daemon_arch.png
Metadata on socket.io¶
This communication is based on an RPC system based on socket.io events sent by Zenko CloudServerconnectors, received by the DMD and acknowledged back to the Zenko CloudServer connector.
The actual payload sent through socket.io is a JSON-serialized form of the RPC call name and parameters, along with some additional information like the request UIDs, and the sub-level information, sent as object attributes in the JSON request.
With introduction of versioning support, the updates are now gathered in the dmd for some number of milliseconds max, before being batched as a single write to the database. This is done server-side, so the API is meant to send individual updates.
Four RPC commands are available to clients: put, get, del
and createReadStream. They more or less map the parameters accepted
by the corresponding calls in the LevelUp implementation of LevelDB.
They differ in the following:
- The
syncoption is ignored (under the hood, puts are gathered into batches which have theirsyncproperty enforced when they are committed to the storage) - Some additional versioning-specific options are supported
createReadStreambecomes asynchronous, takes an additional callback argument and returns the stream in the second callback parameter
Debugging the socket.io exchanges can be achieved by running the daemon
with DEBUG='socket.io*' environment variable set.
One parameter controls the timeout value after which RPC commands sent end with a timeout error, it can be changed either:
- via the
DEFAULT_CALL_TIMEOUT_MSoption inlib/network/rpc/rpc.js - or in the constructor call of the
MetadataFileClientobject (inlib/metadata/bucketfile/backend.jsascallTimeoutMs.
Default value is 30000.
A specific implementation deals with streams, currently used for listing
a bucket. Streams emit "stream-data" events that pack one or more
items in the listing, and a special “stream-end” event when done.
Flow control is achieved by allowing a certain number of “in flight”
packets that have not received an ack yet (5 by default). Two options
can tune the behavior (for better throughput or getting it more robust
on weak networks), they have to be set in mdserver.js file directly,
as there is no support in config.json for now for those options:
streamMaxPendingAck: max number of pending ack events not yet received (default is 5)streamAckTimeoutMs: timeout for receiving an ack after an output stream packet is sent to the client (default is 5000)
Data exchange through the REST data port¶
Data is read and written with REST semantic.
The web server recognizes a base path in the URL of /DataFile to be
a request to the data storage service.
PUT¶
A PUT on /DataFile URL and contents passed in the request body will
write a new object to the storage.
On success, a 201 Created response is returned and the new URL to
the object is returned via the Location header (e.g.
Location: /DataFile/50165db76eecea293abfd31103746dadb73a2074). The
raw key can then be extracted simply by removing the leading
/DataFile service information from the returned URL.
GET¶
A GET is simply issued with REST semantic, e.g.:
GET /DataFile/50165db76eecea293abfd31103746dadb73a2074 HTTP/1.1
A GET request can ask for a specific range. Range support is complete except for multiple byte ranges.
DELETE¶
DELETE is similar to GET, except that a 204 No Content response is
returned on success.
Listing¶
Listing Types¶
We use three different types of metadata listing for various operations. Here are the scenarios we use each for:
- ‘Delimiter’ - when no versions are possible in the bucket since it is an internally-used only bucket which is not exposed to a user. Namely,
- to list objects in the “user’s bucket” to respond to a GET SERVICE request and
- to do internal listings on an MPU shadow bucket to complete multipart upload operations.
- ‘DelimiterVersion’ - to list all versions in a bucket
- ‘DelimiterMaster’ - to list just the master versions of objects in a bucket
Algorithms¶
The algorithms for each listing type can be found in the open-source scality/Arsenal repository, in lib/algos/list.
Encryption¶
With CloudServer, there are two possible methods of at-rest encryption. (1) We offer bucket level encryption where Scality CloudServer itself handles at-rest encryption for any object that is in an ‘encrypted’ bucket, regardless of what the location-constraint for the data is and (2) If the location-constraint specified for the data is of type AWS, you can choose to use AWS server side encryption.
Note: bucket level encryption is not available on the standard AWS S3 protocol, so normal AWS S3 clients will not provide the option to send a header when creating a bucket. We have created a simple tool to enable you to easily create an encrypted bucket.
Example:¶
Creating encrypted bucket using our encrypted bucket tool in the bin directory
./create_encrypted_bucket.js -a accessKey1 -k verySecretKey1 -b bucketname -h localhost -p 8000
AWS backend¶
With real AWS S3 as a location-constraint, you have to configure the location-constraint as follows
"awsbackend": {
"type": "aws_s3",
"legacyAwsBehavior": true,
"details": {
"serverSideEncryption": true,
...
}
},
Then, every time an object is put to that data location, we pass the following
header to AWS: x-amz-server-side-encryption: AES256
Note: due to these options, it is possible to configure encryption by both CloudServer and AWS S3 (if you put an object to a CloudServer bucket which has the encryption flag AND the location-constraint for the data is AWS S3 with serverSideEncryption set to true).